Τα μεγάλα γλωσσικά μοντέλα (Large Language Models – LLM) προτείνονται όλο και περισσότερο ως εργαλεία υποστήριξης κλινικών αποφάσεων. Η αξιοπιστία τους στη διαλογή ασθενών τα Τμήματα Επειγόντων Περιστατικών δεν έχει επικυρωθεί επαρκώς. Μελέτη της Κλινικής Επείγουσας Ιατρικής του ΑΠΘ στο νοσοκομείο ΑΧΕΠΑ επιχείρησε να αξιολογήσει την απόδοσή τους σε ένα μεγάλο αναδρομικό σύνολο δεδομένων.
Οι μελετητές πραγματοποίησαν μια αναδρομική ανάλυση 39.375 ανώνυμων περιστατικών ασθενών από το ΤΕΠ του Πανεπιστημιακού Γενικού Νοσοκομείου ΑΧΕΠΑ στη Θεσσαλονίκη. Ταξινόμησαν τις περιπτώσεις σε πραγματικό χρόνο, σύμφωνα με τον Δείκτη Σοβαρότητας Έκτακτης Ανάγκης (Emergency Severity Index - ESI), και ζήτησαν από 7 μεγάλα γλωσσικά μοντέλα να κάνουν κι εκείνα την αξιολόγηση.
Συγκρίνοντας τις αξιολογήσεις τους με το πρότυπο αναφοράς των γιατρών, διαπίστωσαν πως ο βαθμός συμφωνίας διέφερε μεταξύ των LLM, αλλά κανένα από αυτά δεν έφτασε σε ικανοποιητικά επίπεδα. Το συμπέρασμα της μελέτης είναι πως τα τρέχοντα LLM επιδεικνύουν πολλά υποσχόμενη αλλά ασυνεπή ικανότητα στη διαλογή. Υπό αυτό το πρίσμα, είναι πιο κατάλληλα ως εποπτευόμενα εργαλεία υποστήριξης αποφάσεων, ιδιαίτερα σε καλά καθορισμένα κλινικά σενάρια, παρά ως αυτόνομα συστήματα διαλογής στα ΤΕΠ.
Η μελέτη
Τα 39.375 επείγοντα περιστατικά που συγκεντρώθηκαν αναδρομικά από τα ΤΕΠ του ΑΧΕΠΑ αφορούν την περίοδο 1η Ιουνίου 2024 έως τις 21 Ιουλίου 2025. Αφαιρέθηκαν τα στοιχεία ταυτοποίησης των ασθενών (ονόματα, αριθμοί ιατρικών αρχείων και ημερομηνίες γέννησης) και συμπεριλήφθηκαν μόνο η ηλικία τους (0 ως 106 έτη) και τα συμπτώματα που παρουσίαζαν, καθώς και τα ζωτικά σημεία και το επίπεδο συνείδησης όταν τεκμηριώθηκαν κατά τη διαλογή.
Όλες οι περιπτώσεις ταξινομήθηκαν με τον Δείκτη Σοβαρότητας Έκτακτης Ανάγκης (ESI) από 25 γιατρούς, ενώ σε περιπτώσεις αβεβαιότητας ζητήθηκε η γνώμη ανώτερου γιατρού επειγόντων περιστατικών.
Οι κλινικές πληροφορίες δόθηκαν σε επτά Μεγάλα Γλωσσικά Μοντέλα (ChatGPT-5 Thinking, ChatGPT-5 Instant, Gemini 2.5, Qwen 3, Grok 4.0, Deep Seek v3.1 και Claude Sonnet 4) ώστε να αξιολογηθούν σε σχέση με το επίπεδο ESI που έχει ορίσει ο γιατρός (πρότυπο αναφοράς). Τα αποτελέσματα περιλάμβαναν συμφωνία βαθμολογίας διαλογής, ακρίβεια παραπομπής κλινικής και πρόβλεψη εισαγωγής.
"(…) απαιτώ από εσάς να εφαρμόσετε προσεκτικά τις διακρίσεις και τους αλγόριθμους λήψης αποφάσεων του συστήματος διαλογής πέντε επιπέδων ESI και να υπολογίσετε την αντίστοιχη βαθμολογία για κάθε ασθενή", αναφέρεται μεταξύ άλλων στις συγκεκριμένες οδηγίες που δόθηκαν στα γλωσσικά μοντέλα, από τα οποία ζητήθηκε, στη συνέχεια, να καθορίσουν την καταλληλότερη κλινική παραπομπής, καθώς και να υποδείξουν αν απαιτείται εισαγωγή στο νοσοκομείο. Οι διαθέσιμες κλινικές αναφοράς είναι: Αγγειοχειρουργική, Καρδιολογία, Καρδιοχειρουργική, Νευρολογία, Νευροχειρουργική, Νεφρολογία, Ορθοπεδική, Παθολογία, Χειρουργική, Ψυχιατρική, Ωτορινολαρυγγολογία, Οφθαλμολογία, Παιδιατρική, Fast-Track, αίθουσα αναζωογόνησης.
Οι επιδόσεις των 7 LLM
Τα αποτελέσματα κατέδειξαν σημαντικές διαφορές ανάμεσα στα διάφορα γλωσσικά μοντέλα, ορισμένα από τα οποία είχαν μεγαλύτερη συμφωνία με τα πρότυπα αναφοράς σε σχέση με άλλα. Κανένα, ωστόσο, δεν πέτυχε ικανοποιητικά επίπεδα συμφωνίας με τις αποφάσεις των γιατρών. Συγκεκριμένα, ανά κατηγορία απόφασης:
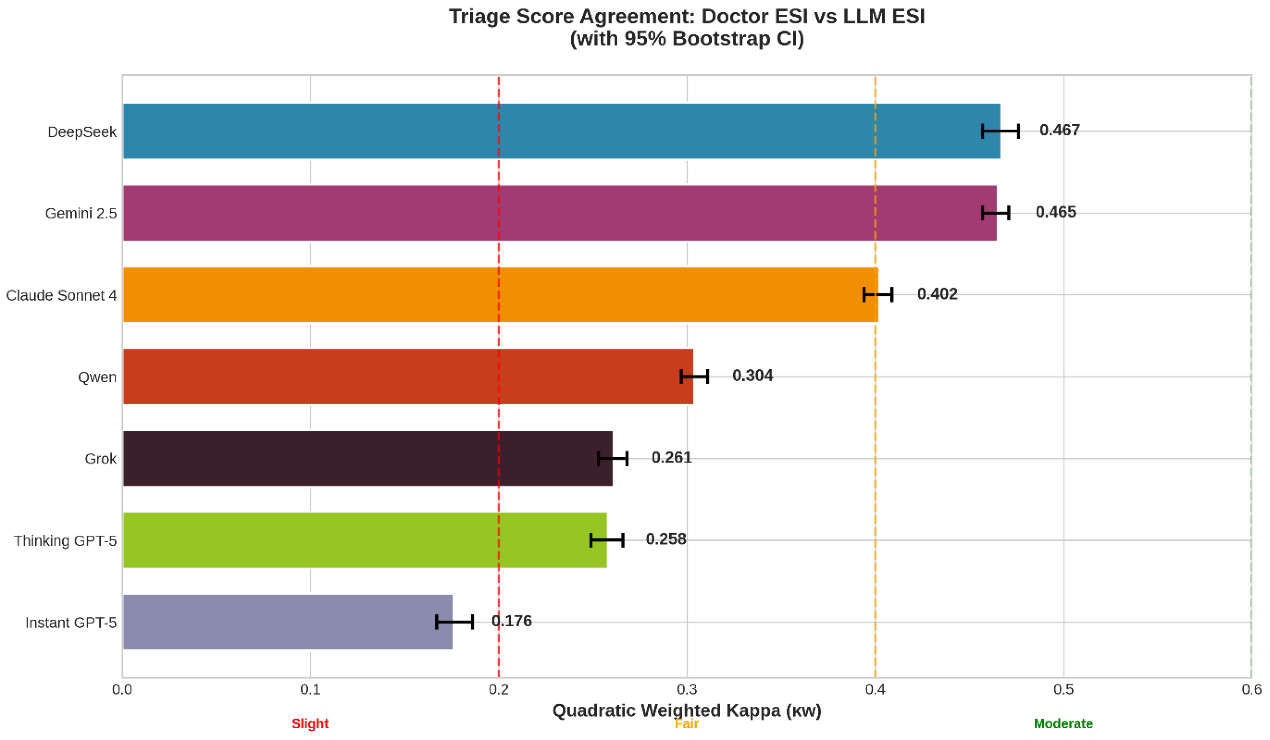
Στη βαθμολογία διαλογής, οι το DeepSeek επέδειξε την υψηλότερη συμφωνία με τις αξιολογήσεις ESI γιατρών (κw = 0,467; 95% CI: 0,457–0,476), ακολουθούμενο από το Gemini 2,5 (κw = 0,465; 95% CI: 0,457–0,471). Και τα δύο μοντέλα πέτυχαν μέτρια συμφωνία. Το Sonnet 4 του Claude έδειξε ελαφρώς χαμηλότερη συμφωνία (κw = 0,402; 95% CI: 0,394–0,409), παραμένοντας στο όριο μεταξύ δίκαιης και μέτριας συμφωνίας.
Μικρότερες συμφωνίες κατέγραψαν τα Qwen (κw = 0,304; 95% CI: 0,297–0,311), Grok (κw = 0,261; 95% CI: 0,253–0,268) και Thinking GPT-5 (κw = 0,258; 95% CI: 0.249–0.266), ενώ το Instant GPT-5 έδειξε κακή συμφωνία με τις αποφάσεις διαλογής γιατρών (κw = 0,176; 95% CI: 0,167–0,186). Σε όλα τα μοντέλα παρατηρήθηκε μια γενική τάση υπερβολικής διαλογής σε σχέση με τις εκτιμήσεις των γιατρών.
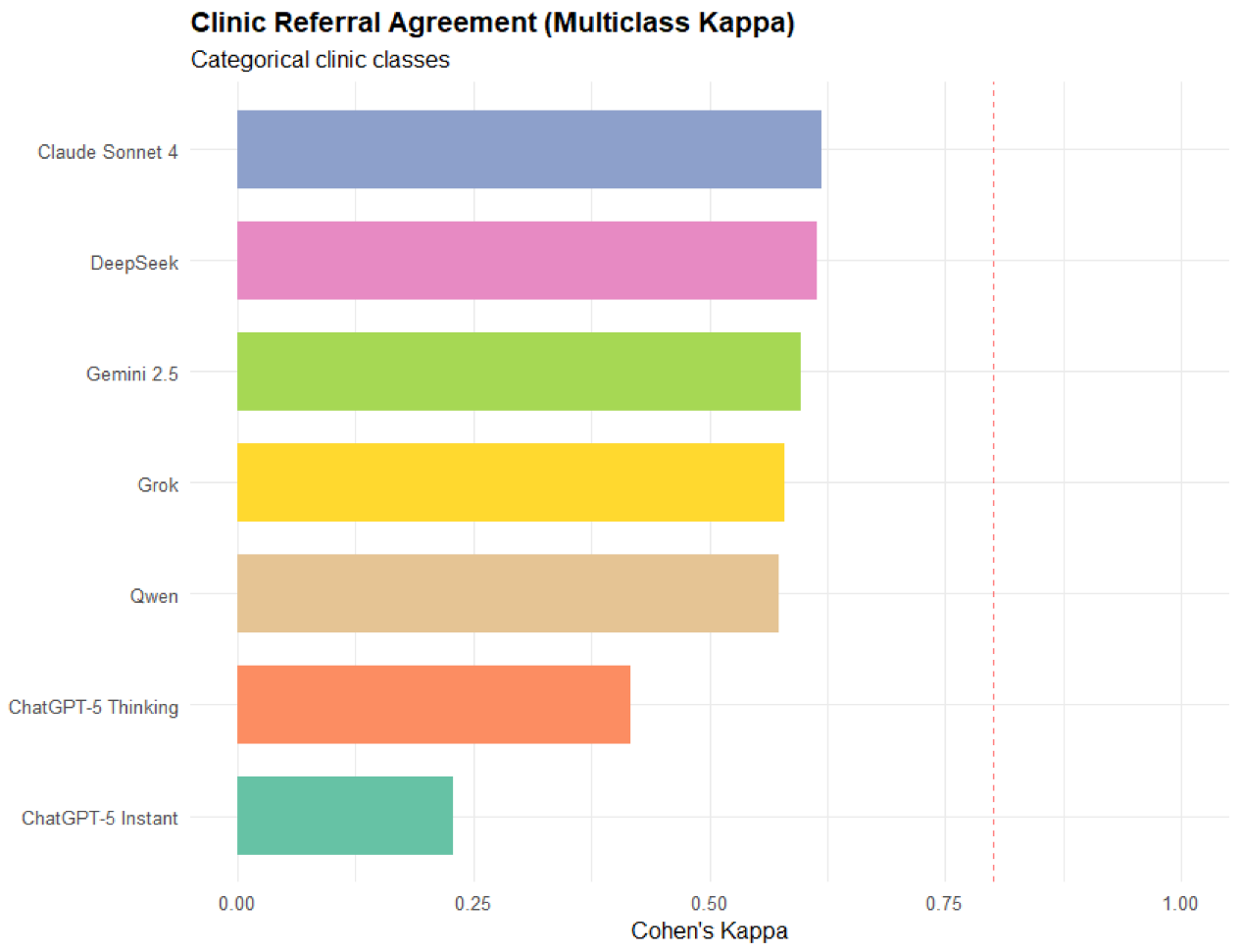
Αναφορικά με τις παραπομπές στις κλινικές, το Claude Sonnet 4 πέτυχε την υψηλότερη συμφωνία με τις αποφάσεις των γιατρών (ακρίβεια: 67,1%, κ = 0,619, 95% CI: 0,614–0,624), που αντιστοιχεί σε ουσιαστική συμφωνία (εικόνα κάτω). Το DeepSeek επέδειξε συγκρίσιμη απόδοση (ακρίβεια: 66,8%, κ = 0,615, 95% CI: 0,608–0,620), ακολουθούμενο από το Gemini 2,5 (ακρίβεια: 64,5%, κ = 0,597, 95% CI: 0,591–0,602) και το Grok (ακρίβεια: 63,8%, κ = 0,580, 95% CI: 0,575–0,586). Το Thinking GPT-5 έδειξε μέτρια συμφωνία (κ = 0.416, 95% CI: 0.411–0.423), ενώ το Instant GPT-5 έδειξε κακή απόδοση (κ = 0.229, 95% CI: 0.224–0.235). Κανένα μοντέλο δεν έφτασε το όριο για ισχυρή συμφωνία (κ > 0,80).
Οι αποδόσεις διέφεραν σημαντικά μεταξύ των κλινικών ειδικοτήτων. Για το μοντέλο με τις υψηλότερες επιδόσεις, η συμφωνία ήταν μεγαλύτερη στην Οφθαλμολογία, την Παιδιατρική και την ΩΡΛ, μέτρια στην Καρδιολογία και στη Νευρολογία και χαμηλότερες στην Ορθοπαιδική και στην Αναζωογόνηση
Σε ό,τι αφορά, τέλος, την πρόβλεψη εισαγωγής στο νοσοκομείο, το Claude Sonnet 4 ήταν το μοντέλο με τις καλύτερες επιδόσεις. Ακολουθούν το Gemini 2.5 και το DeepSeek, με σχεδόν την ίδια απόδοση, ενώ το ChatGPT-5 Instant έδειξε το χειρότερο αποτέλεσμα.
Συμπεράσματα
"Από κλινική άποψη, τα τρέχοντα LLM μπορεί να προσφέρουν αξία ως υποστηρικτικά εργαλεία και όχι ως αυτόνομα εργαλεία λήψης αποφάσεων στη διαλογή", συμπεραίνουν οι μελετητές.
Ενώ επιλεγμένα μοντέλα έδειξαν μέτρια ευθυγράμμιση με τις αποφάσεις ESI του γιατρού και σταθερή απόδοση στις αποφάσεις κλινικής παραπομπής και εισαγωγής, κανένα δεν πέτυχε συμφωνία υψηλού επιπέδου κατάλληλη για αυτόνομη διαλογή. Τα LLM απέδωσαν πιο αξιόπιστα σε ανατομικά καθορισμένα σενάρια και παιδιατρικές περιπτώσεις, αλλά δυσκολεύτηκαν με τη διαλογή με βάση τη σοβαρότητα.
Προσθέστε το iatronet.gr στο DiscoverΕιδήσεις υγείας σήμερα
Τα καλύτερα λαχανικά για την καρδιά διαφέρουν για άντρες και γυναίκες [μελέτη]
Η τεστοστερόνη επηρεάζει τα συναισθήματα των έφηβων κοριτσιών [μελέτη]
Η τεχνητή νοημοσύνη βελτιώνει σημαντικά την αξιολόγηση ενός είδους επιθετικού καρκίνου
 Η τεχνητή νοημοσύνη βελτιώνει σημαντικά την αξιολόγηση ενός είδους επιθετικού καρκίνου
Η τεχνητή νοημοσύνη βελτιώνει σημαντικά την αξιολόγηση ενός είδους επιθετικού καρκίνου Τεχνητή Νοημοσύνη: Η νέα επανάσταση στην πρόληψη και την έγκαιρη διάγνωση των ασθενειών
Τεχνητή Νοημοσύνη: Η νέα επανάσταση στην πρόληψη και την έγκαιρη διάγνωση των ασθενειών Ο Όμιλος Τσέτη στο Health Nexus Forum 2026 στο Βέλγιο για την ΑΙ στην Υγεία
Ο Όμιλος Τσέτη στο Health Nexus Forum 2026 στο Βέλγιο για την ΑΙ στην Υγεία Η τεχνητή νοημοσύνη διαγιγνώσκει όγκους εγκεφάλου σε λίγα λεπτά αντί για εβδομάδες
Η τεχνητή νοημοσύνη διαγιγνώσκει όγκους εγκεφάλου σε λίγα λεπτά αντί για εβδομάδες Ρωτώντας τον..."Doctor AI" - Οι κίνδυνοι της "διάγνωσης" από τα μεγάλα γλωσσικά μοντέλα
Ρωτώντας τον..."Doctor AI" - Οι κίνδυνοι της "διάγνωσης" από τα μεγάλα γλωσσικά μοντέλα Εμβόλιο που σχεδιάστηκε με τη βοήθεια της Τεχνητής Νοημοσύνης δοκιμάστηκε σε ανθρώπους
Εμβόλιο που σχεδιάστηκε με τη βοήθεια της Τεχνητής Νοημοσύνης δοκιμάστηκε σε ανθρώπους Σημάδια ότι το δέρμα σας χρειάζεται ενυδάτωση
Σημάδια ότι το δέρμα σας χρειάζεται ενυδάτωση Τα καλύτερα λαχανικά για την καρδιά διαφέρουν για άντρες και γυναίκες [μελέτη]
Τα καλύτερα λαχανικά για την καρδιά διαφέρουν για άντρες και γυναίκες [μελέτη] Η τεστοστερόνη επηρεάζει τα συναισθήματα των έφηβων κοριτσιών [μελέτη]
Η τεστοστερόνη επηρεάζει τα συναισθήματα των έφηβων κοριτσιών [μελέτη] Νέος προγνωστικός δείκτης για τον καρκίνο του πνεύμονα: Τα "παραμελημένα'' ανοσοκύτταρα αποκαλύπτουν τις πιθανότητες επιβίωσης
Νέος προγνωστικός δείκτης για τον καρκίνο του πνεύμονα: Τα "παραμελημένα'' ανοσοκύτταρα αποκαλύπτουν τις πιθανότητες επιβίωσης Πώς φεύγει το λίπος από το ήπαρ
Πώς φεύγει το λίπος από το ήπαρ Αγαπηδάκη: Σε 15 ημέρες λύση για τα φάρμακα κατά της παχυσαρκίας
Αγαπηδάκη: Σε 15 ημέρες λύση για τα φάρμακα κατά της παχυσαρκίας SheMed: Μια συμμαχία για τη γυναίκα γιατρό και τη γυναικεία υγεία
SheMed: Μια συμμαχία για τη γυναίκα γιατρό και τη γυναικεία υγεία Αγιος Σάββας: Το ιατρικό ανακοινωθέν - αναγγελία θανάτου για τη Μάρω Κοντού
Αγιος Σάββας: Το ιατρικό ανακοινωθέν - αναγγελία θανάτου για τη Μάρω Κοντού Ο Κωνσταντίνος Μεφσούτ στο τιμόνι της Γενικής Διεύθυνσης του PhARMA Innovation Forum
Ο Κωνσταντίνος Μεφσούτ στο τιμόνι της Γενικής Διεύθυνσης του PhARMA Innovation Forum 9 εξακριβωμένα οφέλη του κολοκυθόσπορου
9 εξακριβωμένα οφέλη του κολοκυθόσπορου Βασιλακόπουλος για τη σαλμονέλα στη Λαμία: ''Να μην καταναλωθεί κοτόπουλο για 2-3 ημέρες στη Λαμία''
Βασιλακόπουλος για τη σαλμονέλα στη Λαμία: ''Να μην καταναλωθεί κοτόπουλο για 2-3 ημέρες στη Λαμία'' Ποια ουσία επιβαρύνει νεφρά και καρδιά με φλεγμονές
Ποια ουσία επιβαρύνει νεφρά και καρδιά με φλεγμονές